情感文本短篇_干货:完全基于情感词典的文本情感分析
原文链接:
在金融数据呈爆炸式下降状况下,金融舆论数据的情感分析得到广大股民和金融公司的热切关注。作者强调一种基于短语的对于金融数据情感分析的方式:将一篇短文本划分为不同的个别并予以不同的权重,再以词汇为基本颗粒进行分数计算;同时,在已有的权威字典的基础上,针对性的添加或更改金融方面的术语,并且使用N-Gram方法来进行新词的挖掘,最终赢得更好的性能。
一、介绍:
诚然,目前没有一种模型可以含括所有的领域,也没有一种字典囊括不同领域的术语。

根据需求,我们将精力放到了金融领域,并且收集了不同来源的高品质的数据集。同时情感文本短篇_干货:完全基于情感词典的文本情感分析,我们对一个包括大多数领域的字典进行了更改,添加和设置了金融方面的专业词汇。由于金融数据的直观性、简洁性特征,我们忽视了术语之前的同义、反义等复杂关系,讲更多的精力投入在针对极性的确认和极性程度的判断方面。在此基础上,设计了一个实用的考量金融文本情感的算法模型。
二、数据准备:
从主要金融的沙龙中获得相关的评论数据然后进行数据清洗。
为了保留新闻媒体针对关键词的标注,在数据收集的之后保留了相应的网站标签和繁体风格。之后的检查工作中看到网页的标签的好处可以忽视不计,因此将原本的网页文本清洗成了简体无标签的文本方式。
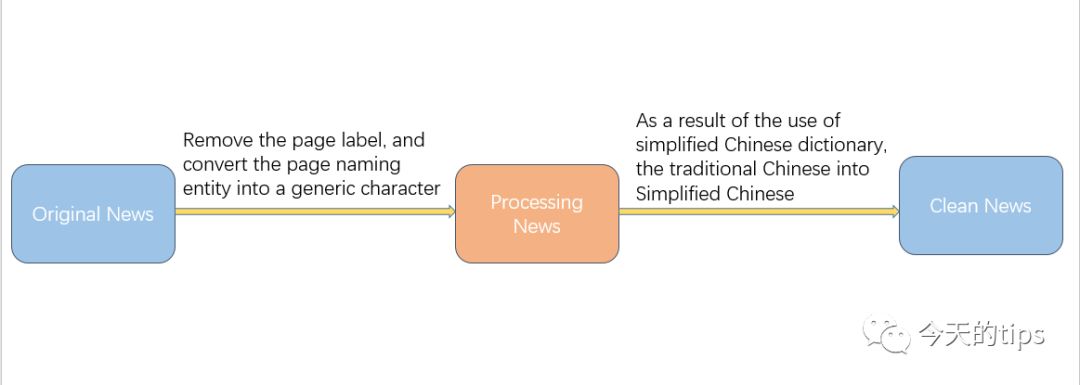
如上图图示,考虑到后来使用的是简体中文词典,因此必须将原始文本进行相应的转化。转换后的文本传输在MySQL和手机的文本格式文件中。
三、字典:
3.1.词典来源
由于算法模型是基于短语的情感分析,所以字典的确切性和灵活度针对结果的妨碍至关重要。字典来自知网的情感词库,原始字典按照习惯将术语分为三大类:
1.情感词
-积极评价词
-积极情感词
-消极评价词
-消极情感词
2.程度词:从最重的most程度依次增加到least程度,共5个等级。
3.否定词
基于以上特征,否定词的存在可以拿来判别是否进行词汇的极性反转,程度词的存在可以给与不同的感情词不同的分数,而情感词可以融合成积极词和负面词两个别。基于知网词库的以上特征,将此词库选做基本的情感词典。
3.2词典的数据类型
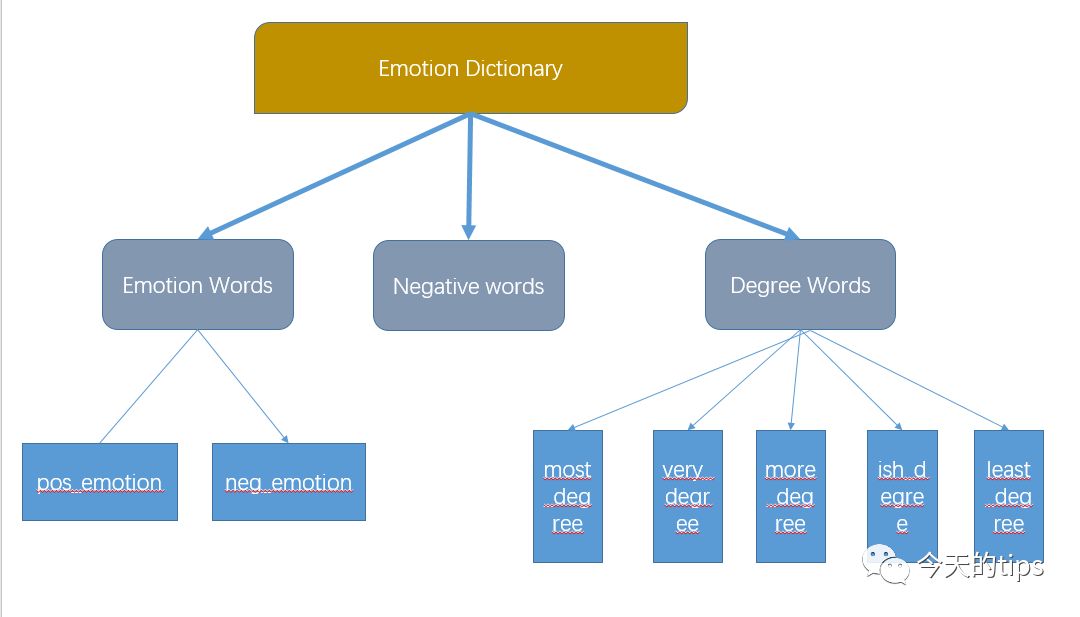
为了让后期的程序更好的调用词典情感文本短篇_干货:完全基于情感词典的文本情感分析,并且让其对方员更易于的更改词典,将文本txt格式的字典按照分类不同放在不同命名的列表中,使得对应的逻辑更直观,方便其它程序读取。
3.3词典的修改
因为知网的词典是对于所有的领域,因此在金融领域术语的界定上不免有失偏颇,前期我采取人工的方式对词典的三大分类进行了略微调整。调整如下:
1.在积极词()中删除了要,用,开通,需,向,应,欲,通,深,对,会,长,常,上,经济,主要,红,幽,灵,颖,硬,不变,是,明显,约,刚,刚刚,到,事实上,基,基部,基础,基础性,固,固定,可乐,谨,主导,自行,增加了'坚挺','新高','利好','放宽','提升','看好','优于','高于','扭转','买超','强劲','反弹','增','缓解','微升','划算','升高','进展','上升','落实','涨','回升','高开','上涨'。
2.在消极词()中删除了大,怊,悭,悱,愦,胜,偏,增加了'倒退','下试','不利因素','紧缩','劝退','乏力','齐挫','贸易矛盾','矛盾','拖累','回落','负债','跌','跳水','鸡肋','沙尘暴','阴霾','钱荒','压力','贬值','利淡','下降','造淡','极端','欠佳','走低','急跌','重挫','周跌','月跌','连跌','背驰','缩减','妨碍','强拆','批评','故障','致歉','减速','减弱','衰退','下滑','严重','急转直下','灰飞烟灭','偏软','丑闻','贪污','倒退','急挫','挫','低见','跌','冲击','大跌','涉嫌','亏损','下跌','纪律处分','处分','赤字','缩水','打击','开门黑','降低','追讨','违法','警告','阴影','变数','不佳','落幕','违法行为','违约金','欺诈','隐患','暴跌','跌穿','受压','连累'
3.在否定词中删除了偏,增加了'无','不','不是'
4.在程度词中增加了'百分之百','特别','重大',"大幅",'半点','小幅'
3.4命名实体的添加
因为分词采用的是第三方Jieba词库[1],为了提高分词情况,对于金融领域常用的命名实体,例如:美联储(金融机构)、吉利汽车(公司/企业)、港股(股票)等进行了添加,以此来降低分词的出错率,提高算法具体度。
四、情感分词算法
4.1文本分块
一篇文本,通常由不同的个别的构成,而每个个别的重要程度不同。对于一篇金融新闻,在文本长度足够的状况下,给定'',''这两个参数,分别代表[0:]句和[-1:]句。这两个别分数的权重()相比于中间部分[:]的权重更高。
其实,当一篇文本过短时,我们觉得它不够足够长来进行分块,即[0:]∩[-1:]≠?,此时将忽略''情感文本短篇,''这两个参数,全文采用统一权重来计算分数。
为了避免首尾权重()针对文本整体的制约过大,以至于算法忽略文本[:]部分的分数,我们将首尾的部分得出的分数除以对应的速率,即:
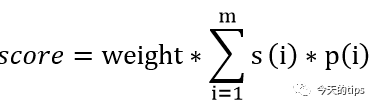
公式:用于[0:]和[-1:]两部分。其中s对应每部分积极或负面情感分数,p对应每部分积极词或负面词的频度,w是每部分的权重。
4.2积极词/消极词
针对中文(无边界语言)界定词语,考虑到速度和第三方库的看到新词能力,我们使用了jieba分词库。将文本中的切实词和负面词结合词典挑选出来,并且每位给予一个分数,在此基础上,我们进行极性反转和程度词的看到。
4.2.1极性反转
词语的极性不必定只由原本决定,一些否定词的使用会让句子的极性反转。考虑下面两种最常用的状况(‘’号代表jieba词库的动词结果):
1.不是不好
2.不是很不好
然而可以看到需要在词语的位置向前搜索1或2个位置,来查找否定词,然后进行极性反转。
4.2.2程度词搜索
针对不同的情感词,每个情感词的分数绝对值的大小取决于程度词。因此类似于极性反转,程度词的搜索采取同样的方式,这里,我们也考虑两种常用的状况(‘’号代表jieba词库的动词结果):
1.非常不好吃
2.不是很好吃
由此可见,程度词的发生位置和否定词相同。同样的,我们在词汇的位置处向前搜索1或2个位置,根据程度词的程度大小,对分数除以不同的系数。
4.2.3公式计算
此外,之前的公式右式中的(i)可以写成以下的格式:
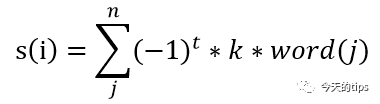
公式:-1的指数t取决于能否极性反转,k代表的是程度词的程度,word(j)是每个词的原始分数。
4.3基于程度词频的优化
实际运行过程中,我看到程序的时间很长,尤其是针对长文本的之后。究其理由,是在之前的极性反转和程度词的判定中,为了穷尽常见的状况,子分支的判定语句更加多。为了避免程序在子分支语句方面判定的时间消耗,采用赫夫曼树[2]的优化思想:将'if-else'理解成递归树,由于不同的程度词在日常语言中发生的频率是不同的,因此,可以将''和''首先判断,再依次判断''、''和'',来超过树的加权模式最小的目的,实现对算法性能的改进。
4.4首尾权重的调优
在第一个公式中,针对首尾两个别的情感分数的计算是有参数''。这里我挑选了2017年5月底第一个交易周的所有样本进行了人工新闻情感的标注。在此基础上,设置''的调整步长为0.1,从1开始,以(1,5]为区间,计算每个''的给与的精确度,来选出最优的''参数。
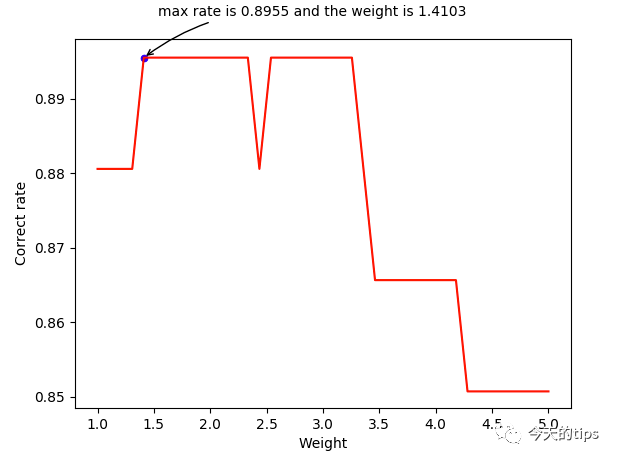
从图中显而易见的看见,正确率最高是89.55%,对应的权重是1.4103。因此,我们将权重设置为1.4103。
4.5分数界线的确定
在实际的测试过程中,我看到一些状况下,当分数过大的之后,结果通常是不确切的。比如有些之后分数超过
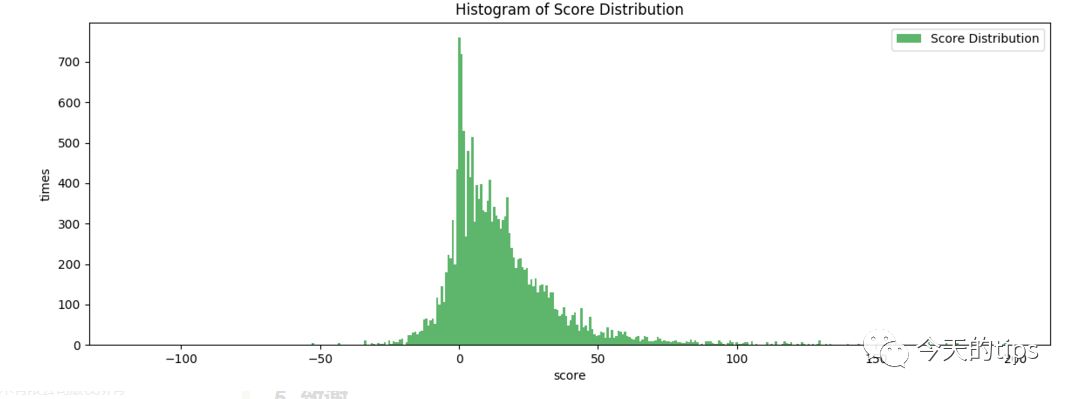
惊人的40多分,文本信息容量过大,不能简单说其是积极或负面或中性的。为了缓解这一问题,首先忽略分数的符号情感文本短篇,即:取分数的绝对值(|score|);但是选择以测试样本最多和时间最靠近的2016上半年,统计分数的在上半年的状况。结果如右图图示。
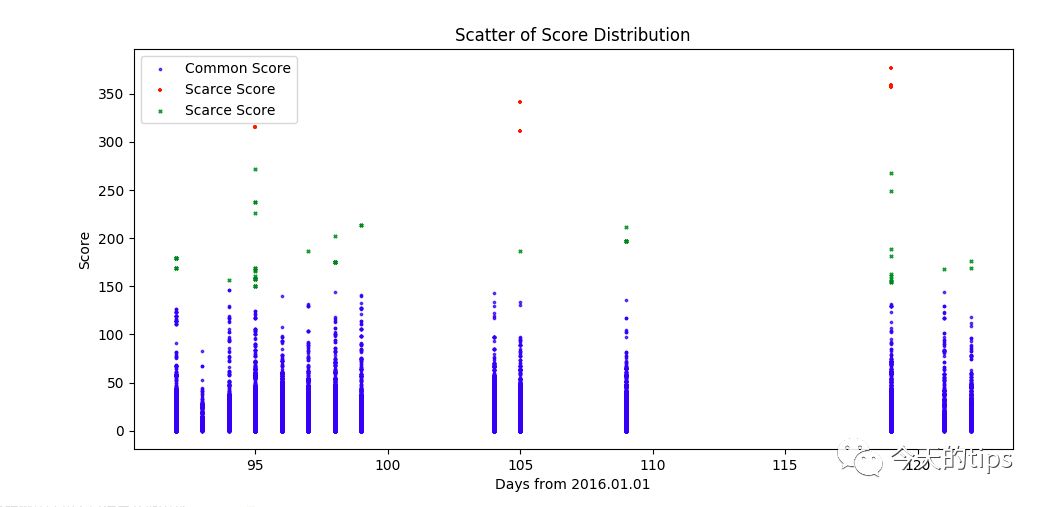
容易看到,150分以上的分数出现的几率特别小(样本容量17710)。因此,我们在随后的预测中,针对这个算法模型得出的分数,专门检测150分数以上对应的新闻,由此来确认突发状况以及识别无用的新闻。在此基础上,我又选择了2016年季度的新闻分数,并且作出了相应的频度分布直方图。